本文共 5234 字,大约阅读时间需要 17 分钟。
论文名称:Enhancing Content Planning for Table-to-Text Generation with
Data Understanding and Verification
论文作者:龚恒,闭玮,冯骁骋,秦兵,刘晓江,刘挺
原创作者:龚恒
论文链接:https://www.aclweb.org/anthology/2020.findings-emnlp.262.pdf
本文转载自【哈工大SCIR】
数据到文本生成任务是文本生成的重要研究任务之一,其目标是根据输入的结构化数据自动生成相关的描述性文本。该类任务需要解决两项挑战:如何从冗余的结构化数据中选择重要信息(内容规划阶段)、如何用自然语言的形式正确地描述重要信息(表层实现阶段)。前人的工作指出目前的主要瓶颈是内容规划阶段。
本文中,我们针对内容规划阶段,提出了数值数据理解和重要信息验证模块,前者通过基于表格上下文的数值表示模块,为模型引入数值大小的概念,帮助模型更好地理解数值数据之间的关系,从而更好地挖掘重要信息。后者,通过策略梯度方法,从内容选择和排序等多个角度指导模型有针对性地优化自己的内容规划能力。我们在两个公开数据集上进行了实验,在内容规划类指标上证明了我们模型的有效性。
本期AI TIME PhD直播间,我们有幸邀请到了该论文的作者,哈尔滨工业大学的博士生龚恒,为大家分享这项研究工作!

龚恒:哈尔滨工业大学社会计算与信息检索研究中心(SCIR)博士三年级研究生,导师为秦兵教授。主要研究方向为数据到文本生成,个人主页:http://ir.hit.edu.cn/~hgong/

1. 简介
数据到文本生成任务是文本生成的重要研究任务之一,其目标是根据输入的结构化数据自动生成相关的描述性文本。以图1为例,输入的结构化数据是一场体育比赛中球员和球队的一系列统计数据,输出的是对应的赛事报道[1]。该类任务需要解决两项挑战[2]:如何从冗余的结构化数据中选择重要信息(内容规划阶段)、如何用自然语言的形式正确地描述重要信息(表层实现阶段)。前人的工作[2]指出目前的主要瓶颈是内容规划阶段。本文中,我们针对内容规划阶段,提出了数值数据理解和重要信息验证模块,前者通过基于表格上下文的数值表示模块,为模型引入数值大小的概念,帮助模型更好地理解数值数据之间的关系,从而更好地挖掘重要信息。后者,通过策略梯度方法,从内容选择和排序等多个角度指导模型有针对性地优化自己的内容规划能力。我们在两个公开数据集上进行了实验,在内容规划类指标上证明了我们模型的有效性。
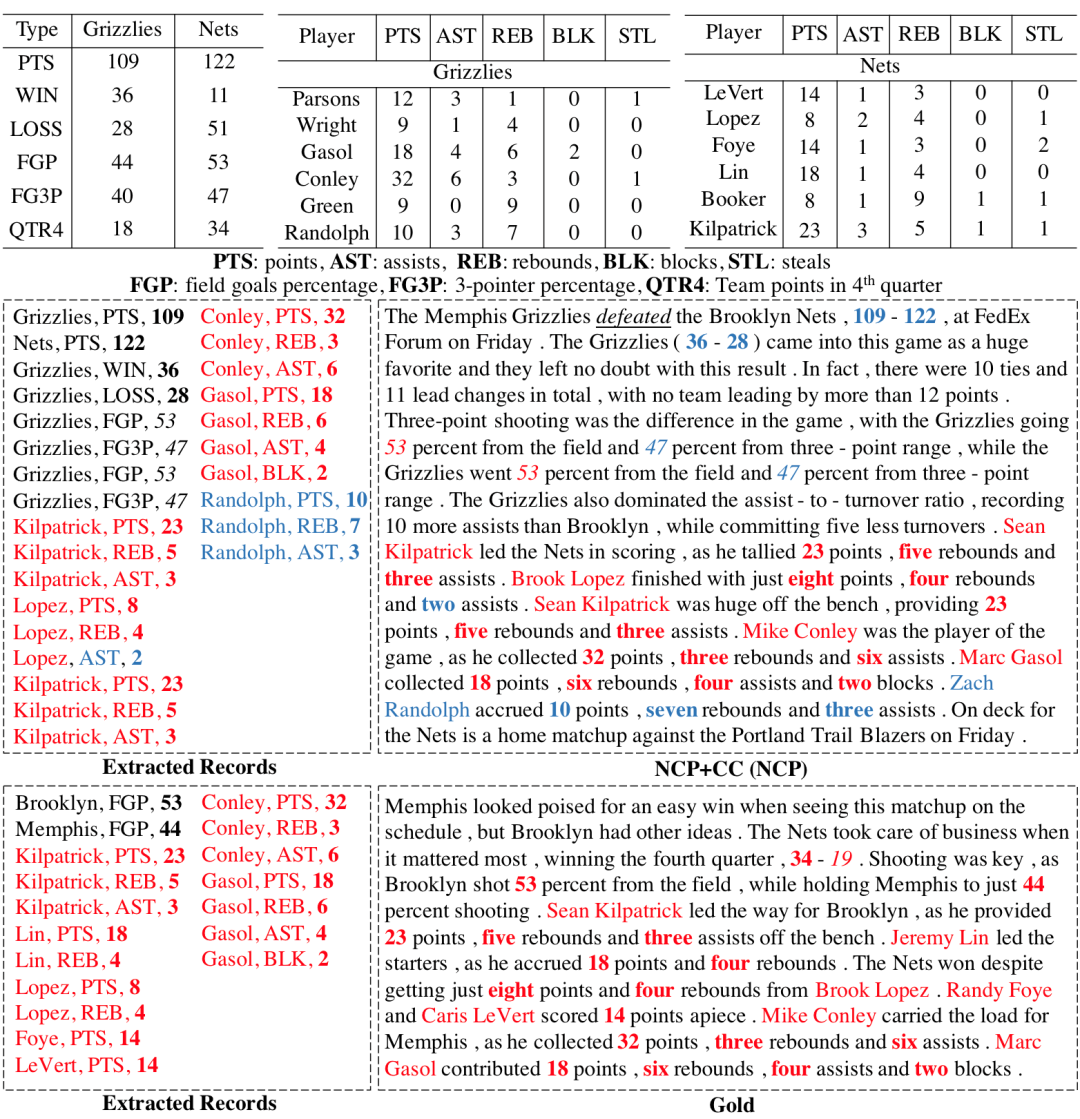
图1 任务示例,NCP是基线模型生成的结果,Gold是参考文本。Extracted Records是文本中提到的数据。
2. 背景和动机
这个任务上的模型可以分为两大类:传统的流水线模型和端到端模型。流水线模型[3,4]将整个任务划分为多个阶段,依次生成。其中,主要的阶段包括内容规划(stage 1,选择和排序重要信息)和表层实现(stage 2,用自然语言对重要信息进行描述),而大多数端到端模型直接根据输入的结构化数据,生成对应的文本[5,6,7,8,9]。Puduppully等人[2]提出了一个两步生成模型(NCP),在保持端到端模型生成连贯文本的能力的同时,允许对模型的内容规划能力进行显式优化。他们的结果显示,模型的内容规划能力离它的上限还有很大的距离,也是制约整个数据到文本生成任务的瓶颈。根据我们的观察,输入的某项数据是否应当被提及和这项数据对应的数值相关,而NCP等模型将数值视为词进行建模,缺少对数值关系的建模。以图1为例,球员Lin得分18,在所在球队中排名第2,他的相关统计数据应当属于重要数据,但是却被NCP忽略了,我们认为这与模型缺少在表格上下文中建模数值信息间的关系有关。这还会影响到表层实现的效果。仍然以图1为例,虽然Nets队比Grizzlies队得分高,但是NCP生成文本的时候却说Grizzlies队打败了(defeated)Nets队。另外,目前的模型采用最大化似然估计(MLE)的方法来优化内容规划模块,缺少面向内容规划的针对性的优化目标。
为了解决上面提到的问题,我们提出了数值数据理解和重要信息验证模块以增强模型的内容规划能力。3.2和3.3对该方法进行了详细介绍。
3. 方法
3.1 基线模型NCP
基线模型[2]将数据到文本生成过程用两个神经网络进行建模。第一个神经网络首先建模表格内容,然后利用Pointer Network从表格中选择和规划出重要的信息(Content Planning)。第二个神经网络以规划出的重要信息为输入,利用编码器-解码器模型生成文本。
3.2 数值数据理解模块
同样的一个数值在不同的上下文中有不同的含义。例如,一位球员如果拿到了所在队伍的最高分“23”分,那他的表现可以认为非常突出。但如果同球队有另外一个球员拿到了“30”分,那拿到“23”分的这位球员的表现相对拿到“30”分的球员来说没有那么突出。有必要建模一个数值在不同上下文中的表示以及数据的大小关系。本文将不同类型的数据(例如得分、助攻、篮板等)视为不同的序列,每一个序列包括各位球员的同一类数据,采用Transformer encoder[10]建模数据间的关系。然后,利用ranking loss预训练这个用来表示数值的Transformer encoder。预训练目标是比较两个数值对应的上下文表示,并分别进行打分,数值较高的上下文表示的得分应当比数值较低的得分高。最后利用数值的上下文表示替换基线模型中数值表示的embedding表示。
3.3 重要信息验证模块
针对内容规划模块,我们定义了五项奖励函数从不同角度衡量内容规划结果的效果。实体重要性(EI)用来判断选择的一项数据描述的实体是否是重要的。实体召回率(ER)用来判断有多少重要的实体被覆盖了。数据重要性(RI)和数据召回率(RR)从数据的层次进行衡量。数据顺序(RO)通过计算编辑距离来判断内容规划的顺序是否自然(和参考文本进行对比)。五项奖励函数通过策略梯度[11]的方法用来优化内容规划模块。
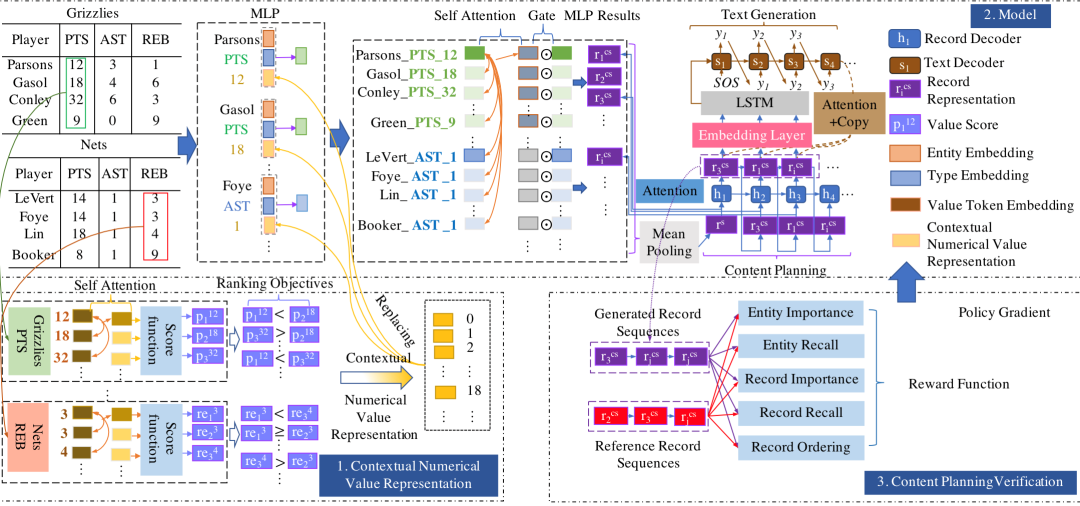
图2 模型结构图。1是我们提出的数值数据理解模块,3是重要信息验证模块,2是基线模型NCP的结构图。
4. 实验
4.1 数据集
我们采用公开的ROTOWIRE、MLB数据集进行训练和测试。
4.2 评价指标
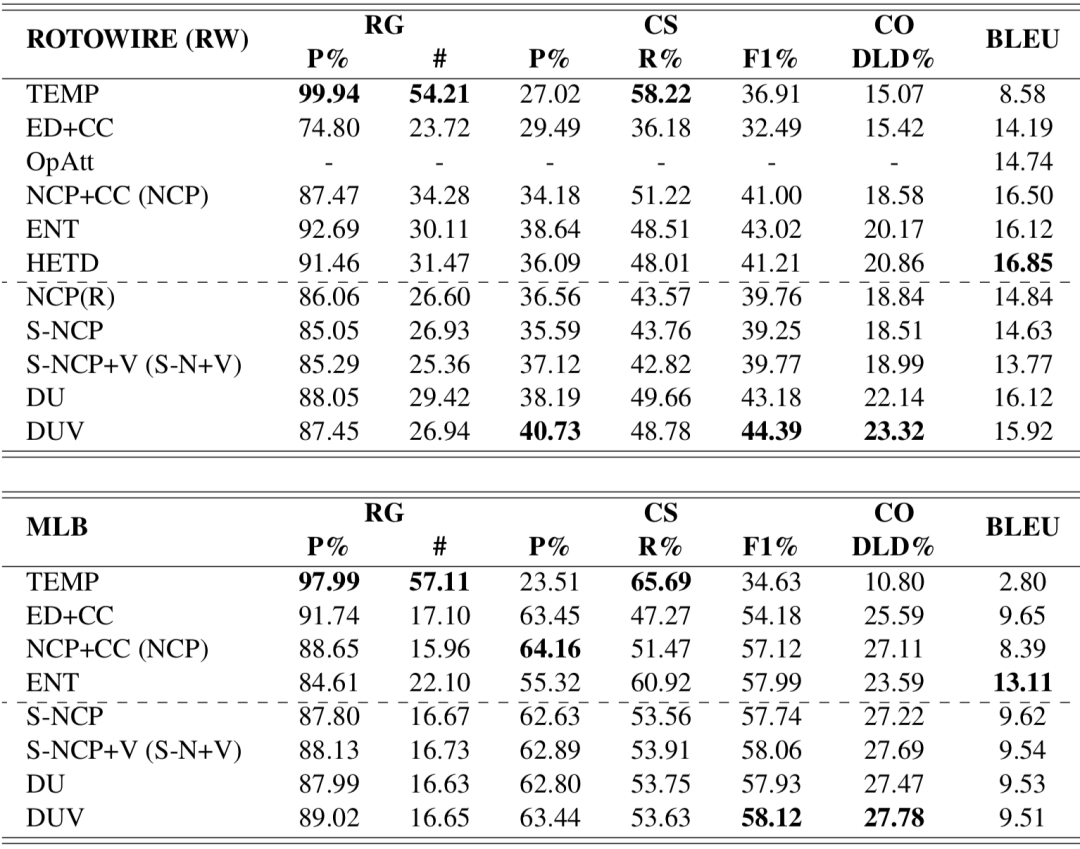
除了文本生成任务上常用的基于N-Gram匹配计算的BLEU值以外,Wiseman[1]等人提出通过训练一个信息抽取模型,从生成的文本中抽取三元组,和表格以及参考文本进行对比进行评价,得到RG、CS和CO三类指标。其中,RG通过对比生成的文本中抽取三元组和表格中的信息判断生成的内容是否正确。CS通过对比生成的文本中抽取三元组和参考文本中抽取三元组,判断生成的内容包含重要信息的能力,CO通过计算生成文本中抽取的三元组和参考文本中抽取的三元组的编辑距离判断生成的文本对于信息的排列是否自然。
4.3 实验结果
我们对比了基线模型、基于模版生成的结果、该数据集上的其他模型等,我们的模型(DUV)在内容规划类指标(内容选择指标CS F1%和内容排序指标CO)超过了其他模型,验证了我们模型在内容规划上的有效性。
表1 实验结果
4.4 生成案例
图3生成的案例体现了我们模型(DUV)生成的文本中的一些优势:
相比基线模型NCP(图1),正确地提到得分更高的Nets队打败了Grizzlies队。
相比基线模型NCP和ENT模型,在覆盖所有重要球员(红色标注)的情况下,过滤了大部分不重要的数据(蓝色标注)。
比较内容规划结果(Planning)和生成文本中提到的信息(Extracted),生成的文本能够比较好地如实反映内容规划阶段选出的重要信息,印证了这项任务的主要瓶颈是内容规划。
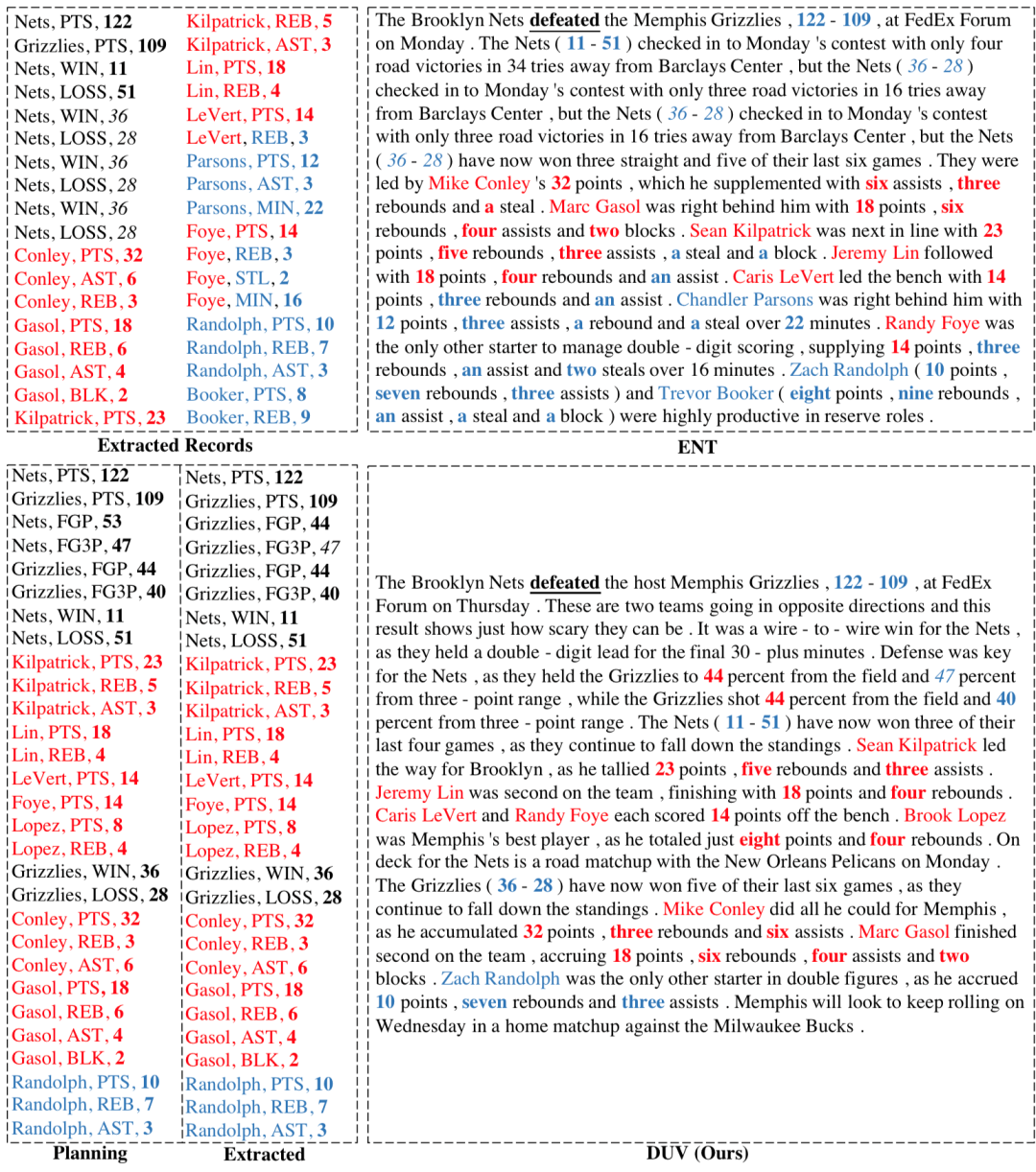
图3 生成案例
5. 结论
本文中,我们针对数据到文本生成的内容规划问题提出了数值数据理解和重要信息验证模块,实验结果表明我们的模型相比之前的模型在内容规划能力上得到提升。
参考文献
[1] Sam Wiseman, Stuart Shieber, and Alexander Rush. Challenges in data-to-document generation. EMNLP 2017.
[2] Ratish Puduppully, Li Dong, and Mirella Lapata. Data-to-text generation with content selection and planning. AAAI 2019.
[3] Karen Kukich. Design of a knowledge-based report generator. ACL 1983.
[4] Kathleen R McKeown. Text generation: using discourse strategies and focus constraints to generate natural language text. 1985.
[5] Liunian Li and Xiaojun Wan. Point precisely: Towards ensuring the precision of data in generated texts using delayed copy mechanism. COLING 2018.
[6] Feng Nie, Jinpeng Wang, Jin-Ge Yao, Rong Pan, and Chin-Yew Lin. Operation-guided neural networks for high fidelity data-to-text generation. EMNLP 2018.
[7] Ratish Puduppully, Li Dong, and Mirella Lapata. Data-to-text Generation with Entity Modeling. ACL 2019.
[8] Hayate Iso, Yui Uehara, Tatsuya Ishigaki, Hiroshi Noji, Eiji Aramaki, Ichiro Kobayashi, Yusuke Miyao, Naoaki Okazaki, and Hiroya Takamura. Learning to Select, Track, and Generate for Data-to-Text. ACL 2019.
[9] Heng Gong, Xiaocheng Feng, Bing Qin, Ting Liu. 2019. Table-to-Text Generation with Effective Hierarchical Encoder on Three Dimensions (Row, Column and Time). EMNLP 2019.
[10] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention is all you need. NIPS 2017.
[11] Richard S Sutton and Andrew G Barto. Introduction to reinforcement learning, volume 135. 1998.
本期责任编辑:李忠阳
本期编辑:彭 湃
『哈工大SCIR』公众号
主编:车万翔
副主编:张伟男,丁效
执行编辑:高建男
责任编辑:张伟男,丁效,崔一鸣,李忠阳
编辑:王若珂,钟蔚弘,彭湃,朱文轩,冯晨,杜佳琪,牟虹霖,张馨
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至yun.he@aminer.cn!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(直播回放:https://b23.tv/ze6EmV)
(点击“阅读原文”下载本次报告ppt)